Machine Learning: Probability to Decision-Making
Hello and welcome to GearsNGenes’ online course on machine learning. In this course we will journey through how we use basic probability, some calculus, and good old programming to create computer applications that give the illusion of life. But before we go any further, we need a bit of context for this course will actually cover.
A Prologue: What is Machine Learning?
Machine learning, Artificial Intelligence, Computer Vision, and Natural Language Processing. These terms seem to go hand in hand, referring to machines or applications that can learn and perform tasks without human assistance, to some extent better than with human assistance.
But in reality, machine learning, artificial intelligence, and computer vision serve more complex and distinct purposes. And no, the Terminator is far from being a reality.
In truth, there exists a hierarchy and relationship between these terms can best be understood with the following diagram:
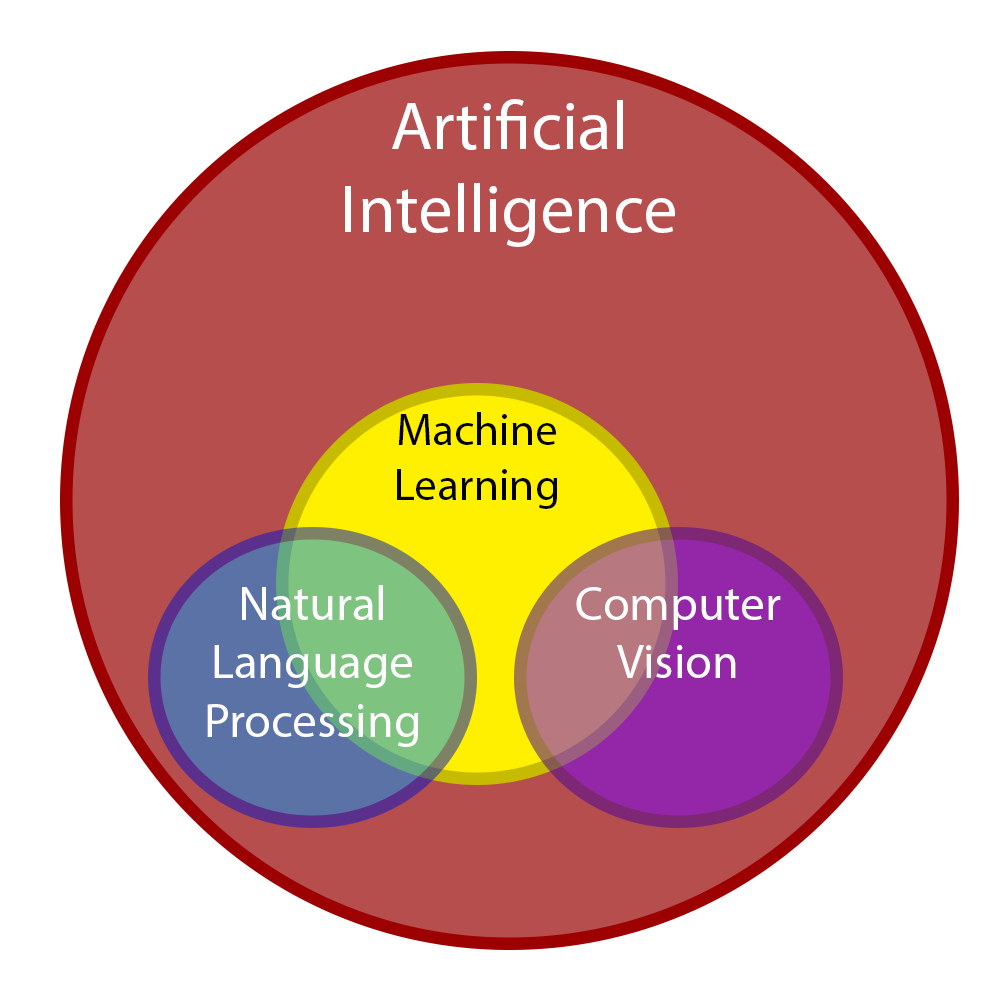
As you may notice, artificial intelligence is the broadest of these categories. Of the listed terms, AI is the most vague, thus its boundaries and what it encompasses is rather vague. Wikipedia mentions two common interpretations of the hierarchy through similar Venn diagrams, which you can check out here.
Stuart Russel in his book Artificial Intelligence; A Modern Approach, 4th edition, simply states that AI has become “the study and construction of agents that do the right thing”, where the right thing depends on what task an application in question is assigned. Other sources claim that its focus is on the development of applications capable of mirroring human behavior and activity. I took the most common aspects of AI that I found and compiled them into the following definition:
Artificial Intelligence focuses on the development of “non-deterministic” tools and algorithms . That is to say, these programs can perform tasks without explicit instructions provided by humans. The outputs and performance of such applications tend to rely on the quality and quantity of information available to them.
By this definition I have constructed, the subsequent terms below are categories within the umbrella term of artificial intelligence. Hence my Venn diagram above.
Machine learning studies how to train programs to make their own decisions when new data is presented to them. For instance, if you wanted a program that could distinguish cat pictures from dog pictures, you would give your model example images of cats and dogs so the model could develop its own definitions.
Computer Vision and Nautral Language Processing are artificial intelligence that are the applications of machine learning outputs. They require machine learning to train themselves to know what they are looking for. Once the model is prepared, the rest of the application can use the model for other tasks. For instance, a cat-dog detector that tracks any dogs or cats on a screen is an example of computer vision, where a learning model created its definition of cats and dogs. Then there is Natural Language Processing, an example of which may be used to create a program to engage in a conversation with a human partner. A learning model had to be trained on the language of its human partner before it could use the model.
This course will primarily focus on the yellow circle of machine learning, which contains the common techniques used these branching fields within AI. We will learn how to design programs that can improve their accuracy at performing tasks. We’ll start from the ground up to see how fundamental concepts like probability, linear algebra, and calculus can be combined to create complex algorithms that enable autonomous decision-making.
*Fun Fact: one of the biggest contributions to the popularity of AI and ML was the creation of ImageNet, a company known for its database of images, which gave ML a concrete example of its helpfulness through computer vision.